We get this question from time to time, and the answer is not as obvious as one might think. I'm about to explain it in-depth, but first, I'll give you a short answer in case you're in a hurry. Please consider the relevant tooltip of Agent:
Hopefully, this explains what to do. You're welcome to suggest better phrasing in the comments, but this is the short and sweet version. And now on to the more detailed explanation.
The most important thing to understand is that USB keyboards (the UHK included) do not send characters to your computer. No, Sir. They send scancodes. When you press a key, a scancode of 1 to 255 gets sent to the computer. It's not a character but a number!
Now think about this: There are 255 different scancodes that must be mapped to more than 100,000 characters that are used on planet Earth! How so? This is how:
Your operating system translates scancodes to characters based on your actual operating system keyboard layout.
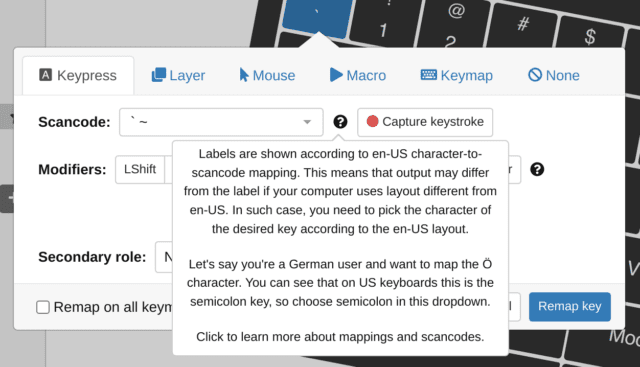
Let me give you an example to make you realize the crucial role of your OS layout. Let's say that an American, a German, and a Russian user purchase USB keyboards of the same physical layout. Now let's take the semicolon key according to the American layout. On all three keyboards, when pressing this key, the scancode 51 gets sent to the computer, yet, the character ";", "ö", and "ж" appear on the screen of the American, German, and Russian users, respectively, merely because they use different OS keymaps.
When it comes to mapping scancodes to characters, the situation is actually slightly more nuanced because modifiers also affect the mapped characters. For example, on the US layout, Shift + 4 produces "$", and on the Hungarian layout, AltGr + U produces "€", but this doesn't alter the nature of the beast.
There's a mechanism called "Alt codes", which allows users to produce various accented characters in a way that is (mostly) independent of the current OS keymap.
Alt codes provide a way to output various characters in a way that is mostly independent of the current OS keymap, but they're OS-specific, and they don't work in every environment. For example, let's say that your hard drive is encrypted, and you have to type a password before the OS boots up. Depending on your OS, Alt codes may not be available at this point. On Linux, they also can't be used in terminals outside of the X server, so you can't rely on them in every environment.
Given that Alt codes are sequences of keystrokes, they're ideally suited to be assigned to keys using UHK macros. For example, you can bind the Alt code of "é" to Mod+e. UHK macros are very handy since they're saved to the on-board memory of your UHK and always available without running special software once you set them up via Agent. I'm about to elaborate on implementing Alt codes on your UHK.
The macro editor of Agent is very intuitive to use, and based on the above, one should be able to create macros that implement Alt codes. There are some gotchas, though.
First up, Alt codes are OS-specific which will pose a problem if you use multiple OSes. If so, you'll have to create all your Alt code macros for every OS you use, and then create OS-specific keymaps in Agent and bind the macros of the respective OSes. This is clearly laborious, but there's no way around it. We won't implement USB fingerprinting in the UHK firmware to detect OSes because it's fundamentally unreliable.
The second gotcha is that you won't be able to compose Alt codes with modifiers. Imagine holding Shift, then typing Alt code key sequences, then releasing Shift. Modifiers clearly mess with Alt codes.
Third, some Alt codes are dependent on the state of your OS. You have to have NumLock enabled for Windows Alt codes, and Mac accent codes are dependent on the OS keymap in use.
Some of you were wondering why Agent doesn't offer or display accented characters. This is one of those features that seem like a no-brainer from a user perspective, but in practice, it's not only incredibly hard to implement but cannot be implemented properly. Let me tell you why.
In order for Agent to expose accented characters, it must be aware of the current OS keymap. Being a cross-platform application, it'd have to query the actual keymap on Linux, Mac, and Windows. A quick search reveals ways to query this information (often rather obscure ways) via OS-specific APIs, but I have found no way to query the actual mappings between scancodes and characters, which is critical.
Without the exact per-key mappings, Agent would have to have a database of every single OS-specific layout, such as "French (Bepo, ergonomic, Dvorak way, Latin-9 only)" or "Russian (Ukraine, standard RSTU)". We could extract such a database from the relevant Linux packages, but these layout names are not standardized, so they're inconsistent across OSes, and the mappings surely differ in some ways.
The bottom line is that it'd take huge resources to implement the above, and we'd end up with a half-assed implementation, given that a perfect implementation is practically infeasible. Even if we were able to implement this perfectly, I don't think it would be a good idea. I can foresee users complaining that they set up the é key in Agent, then plugged their UHK into another machine (featuring a different OS keymap), and the é key suddenly became a semicolon. Users should actually understand how things work when it comes to this topic.
When remapping UHK keys, you should keep in mind that:
That's it, folks! If you're still reading, then you're truly one of the brave few. Any questions, feel free to shoot them in the comments.
You can specify custom scancodes on the UHK. See how.
53 Responses
If I understand this correctly you are saying this isn't possible yet? I first tried to bind the Ö character to ; as per your tooltip but that does just output ; . So basically we should just build macro's but they aren't supported yet. I like the macro idea so I hope it gets implemented soon. because now the keyboard is kinda working half for me ( I have too google the accented characters about 200 times a day)
How exactly did you enter accented characters so far with your other keyboards?
I used azerty layout. They are on the keyboard itself (usually using alt gr + key)
Then why aren't you doing the same on your UHK? AltGr is just right Alt.
For completeness, you missed the best way of typing special characters on linux: AltGr+DeadKeys:
RightAlt + ' and then e becomes: é
RightAlt + = and then e becomes €
etc.
Of course this is limited to the character that are built up of two other characters, but I find this the most intuitive way.
Thanks for mentioning! Dead keys are very handy, and they're more intuitive to invoke than Alt codes, but they're dependent on the actual OS keymap.
I've been rather happy with the ISO UHK, and using the left control as the compose key (also Linux). The dead key layouts I've tried don't mandate a chorded key to activate, so I find myself missing characters or getting one wrong character in place of two that way. This seems to be three keystrokes instead of the two key chord and a keystroke in your method, so it doesn't matter much.
I did have to get used to the ISO shift being something other than shift for times when I just needed a command. For touch typing I never used that part of shift in the first place, so that was perfectly fine for me.
Did you have to do any additional work to get your UHK Alt key to be the compose key on linux? I have my right alt as the compose key but it only works on my laptop's inbuilt keyboard.
As you can see in this image https://en.wikipedia.org/wiki/AZERTY#/media/File:KB_France.svg , the azerty layout has the accented keys on the keyboard itself. For the UHK I switched to the qwerty layout, I assume my problem isn't related to the usage of the UHK but to the qwerty layout.
Yes, your problem is clearly related to the QWERTY OS layout. You will be able use accented characters with your UHK just as with your other keyboards when using the AZERTY OS layout.
Did you read this article? I'm asking because because I've spent hours writing this article, but according to your follow-ups you didn't read it.
I have read the article and most things in it are clear to me. I also understood from it that we are basically waiting for the macro functionality to have an easy way to rebind it with the unicode setup ( I am using Linux).
I apologize for asking this question the wrong way. I assumed at first the problem was related to the UHK but now I realize it was because I selected the keyboard layout wrong. I have now switched to a keyboard layout that supports all the characters I need an is still qwerty. I never even knew this was a thing, because I typed azerty all my life.
I am happy with my UHK now and thank you for the article explaining it in detail.
Keep up the good work!
Thank you for the clarification! We'll do our best to implement macro support soon. We're glad you're happy with your UHK!
I am a french azerty user too and I solved all my UHK issues with the qwerty-fr keyboard layout (http://marin.jb.free.fr/qwerty-fr/). It is basically a qwerty layout but with our beloved french Alt-Gr layer to make all french special characters available.The layout is meant to be quite intuitive once you have grasped its phylosophy.
I haved used the layout you suggested now for a few months, this is a very good solution and I love it. Thanks
Hello,
This keyboard is close to the perfection for me.
But, not be able to setup a full-set like Bepo is really a deception for me.
Maybe you can add solution for guys like me, even a very hacky solution, for example a solution to allow me upload differents exact per-key mappings for my needs and then allow me to customize every key to setup a Bepo
Hi there! I assume Agent issue 617 would solve this problem for you, right? We'll make it happen, but no ETA yet.
For right now, the workaround is to steal the Fn layer (or whichever one you use least) to use for shifted characters. Caps lock, if it changes things oddly, can be done as a separate keymap. It occurs to me that you can probably make another keymap to replace the layer you steal.
This layer workaround does behave a little oddly in terms of trying to use the mouse with shift and certain key combinations are order-sensitive when they should be, but for the most part it works quite well.
Just got my UHK, it‘s great! Thanks for the fn–steal idea! As an adamant Programmer Dvorak user, I will be trying it while patiently waiting for issue #617 to be resolved. =). After that the keyboard will truly be perfect for me. =)
I want to set key by Usage ID.Because Japanese Key mapped UsageID 88h ~ 8Ah.
The next Agent release will contain international scancodes. You will be able to select them in the "International" section of the scancode selector. The scancode names themselves will be general, and won't be very descriptive, such as "International 1" or "Language 2", but there won't be many of them, so it'll be easy to find the one you're looking for by experimenting a bit. There's no solid ETA on the upcoming Agent release. Please keep checking the https://github.com/UltimateHackingKeyboard/agent/releases page. The new release will be the one after 1.2.11.
Great!
This is so heartbreaking xD I searched the universe and back for the perfect keyboard.
Mechanical, Ergonomic, DE Layout...I just can't tick all the boxes this is so frustrating...why did I have to be born a german -.-
We'll eventually provide German keycaps, but no ETA yet. In the meantime, blank may fit your needs, and it should keep away all the people who can't touch type. :)
hmmm...2019? If it is 2019 I guess I wait...I have too many cooperative cooding sessions at my desk xD
If getting close will do, WASD Keyboards will do fully custom printed keycap sets, and have told me they can handle the UHK layout, except some substitution will have to be made for space and backspace. For those keys you'll have to either use the not-quite-matching original UHK keys (what I plan to do when I get around to actually getting a set printed myself), or you can see what options they do have.
Hi Holger, I had similar problems and even had to dig into QMK-coding in order to be able to type proberly (my own christmas gift to myelf will tell whether I was successful). The way I understand it the UHK will work out of the box, only the keycaps might be off.
As a fellow german programmer you should definitely check out the NEO-2 layout on http://neo-layout.org/ Just use it in your free time for checking emails in the evening and within a month you will be able to type as fast as with QWERTZ, but with way more pleasure while programming as you never have to leave the home row again for brackets or numbers.
I'm still new in the Mechanical keyboard comunity. I thought the main problem would be handling the QWERTZ layout because it's so different from the QWERTY.
Keys like {[]} that I use most often as a programmer are all on the number keys.
I also thought I should learn the normal ISO layout because {[]} is easier to access in QWERTY layout and QWERTY is not as big a change as DEVORAK would be.
QWERTY in general has so much more support in terms of mechanical keyboards...
With keyboards, there are two completely separate issues with layouts. What I understand now to be the significant one is what the computer shows for a given typed key. The only difference between the various country specific ISO layouts is the keycap printing. They all send the same scancode for the same physical key, and the computer is set to the relevant country code to make the keyboard legend match what shows up on the computer. If you tell the computer the UHK is a German layout keyboard, it will act like one, regardless of the legends.
What the UHK programming does (and is still a WIP), is to allow you to send different scancodes for a given key so you can plug a UHK into a computer expecting one keycap printing, and have it act as if it is a different keyboard, for example, being able to plug the UHK into a computer expecting a UK English ISO keyboard, and have it send the scancodes so it acts like a German layout keyboard.
For your own keyboard, if you touch type, the labels on the keycaps probably don't matter much, and it should be plug and play on your computer. Just tell your computer the keyboard is your German layout, if it doesn't automatically assume so. If you want a German printed keycap set right away, there are some potential options listed above and linked in recent blog posts.
Really?!?!?! That Sounds perfect! I was a little confused because I wasn't sure that I that would be the case. So if don't modify anything it will work out of the box with PC or mac and as soon as there are German key caps I can just switch them...now that solves it ^^ thanks
Yes, it works that way. I'm also German and use it the same way.
My main OS layout is Colemak and my main UHK layout is QWERTY. German characters I type with the Linux compose key (AltGr + " + a → ä). If I want to type German characters without the compose key I change my OS to QWERTZ layout, UHK layout stays on QWERTY all the time. BTW, for Windows I use a little tool called WinCompose (https://github.com/SamHocevar/wincompose) that emulates Linux' compose key functionality so that I don't have to adapt to the OS I'm using.
The UHK layout comes in handy when I use it with my phone. I set the UHK layout to Colemak which is more convenient than switching Android to Colemak.
.. and I can reassure you that the UHK is the perfect keyboard :-D
you use this keyboard with your phone?
Some do.
Hi Guys,
I read the article and I can't figure it out how I can use alt codes with UHK with windows. I tried to assign Num lock key via agent and try to type ALT 0196 (should give me Ä) but it didn't succeed. How can I do it please ? My goal is to create macro for that german character.
Thanks for any help
The Alt-codes are numpad key specific. The regular numbers on the top row won't do it. When we get more layers you can probably set one to put numpad numbers somewhere on the keyboard or use an alternate layout.
For a macro, configure it to use key actions. If I'm seeing correctly, try press key L-Alt, tap key numpaad code as many times as needed, then release key L-alt. xev indicates a correct send for this.
Tor is spot on, Michal. It's important that numpad number scancodes must be used. It's also worth mentioning that the state of the NumLock is critical. If it's generally enabled then you shouldn't use it in the macro. If it's disabled then the first macro action should enable it and the last should disable it.
Thank you very much guys. I made it working. It's great I love UHK :)
Hi Laszlo,
on your comment: Tor is spot on, Michal. It's important that numpad number scancodes must be used. It's also worth mentioning that the state of the NumLock is critical. If it's generally enabled then you shouldn't use it in the macro. If it's disabled then the first macro action should enable it and the last should disable it.
I tried to use NumLock only in macro (I pressed at the begging NumLock and released at the end) but it doesn't work properly. I get some strange characters between atl code ones. I ended up with enabled NumLock permanently.
Hello! Just came across this article - new UHK user here. I'm interested in adding a keymap to my UHK that outputs Greek alphabet letters as I frequently use these in mathematical expressions. Is there a way to achieve this using Alt-codes? I use Windows as my OS, and I can only see a few greek characters in the corresponding Alt code table (https://www.alt-codes.net/), whereas the full alphabet has many more e.g. https://www.rapidtables.com/math/symbols/greek_alphabet.html
Hi there! I'm afraid that Windows Alt-codes implement only a small subset of all Unicode characters. The linked table seems complete.
In Windows there is a way to unlock additional Alt+ codes in order to be able to access otherwise non-typable unicode characters.
How to do this with a regedit entry is described in Method 1: Universal on https://www.fileformat.info/tip/microsoft/enter_unicode.htm.
There are also other methods described, using the well known (Alt with number sequences or using third software).
You can also search for various characters on the site to find out the Alt+ codes, e.g. Alt +3B1 gives α (alpha) https://www.fileformat.info/info/unicode/char/3b1/index.htm.
But as always, there is a **caveat**. Entering e.g. Alt+02C7 can trigger an Alt+C shortcut in programs like firefox, which breaks it.
Another thing, which is not describe in the link above is the RichEdit feature, which unfortunatly, as far as I know, only works in Microsoft products like WordPad or Word. These programs allow Alt codes greater than 255, e.g. Alt945 gives α (works out of the box, but just in windows programs... argh, but why...)
Feel free, too add this to the blog post above.
Just added your comment to the post. Thanks for sharing this mad wizardry!
Am I being stupid, or is there no way to be able to type both the "£" and "#" characters on this keyboard? On a normal Mac UK keyboard, you can type "£" via Shift-3 and "#" via Option-3. What keypress combo is the same as Option-3? I simply cannot be the first person with one of these keyboards who needs to type both a "£" and a "#".
Ok, I must genuinely be going mad. I tried to assign a macro to type a hash and when that didn't work, I cleared it back out again. I then tried to type the char using its raw Unicode value (23) using the Mac's ability to insert raw Unicode chars by holding down Option and typing its Unicode value. Now, simply hitting Option-3 inserts a #, as I would expect from a normal Mac keyboard. I have no idea why this did not work originally. Anyway, all good now,
Glad to hear it's working now! We have an article on characters vs. scancodes that is worth checking if any confusion arises.
Is there a way to trick keyboard to send scancode for upper-case unicode character when Shift modifier is held down?
I'm running QWERTY PC map on linux, US layout.
Trying to map some keys to type öäü via Mod layer. It works fine after defining alt-code macros. But problem is you can either define upper _or_ lower case combination.
Is it possible to send different macro when Mod+Shift is held down?
The next Agent and firmware version will allow for modifier layers, such as a Shift layer via which mapping Shift+key will be possible, but Mod+Shift+key won't be supported. The latter scenario may be implemented by Karel's UHK firmware fork.
While I appreciate the lengthy article, 99% people who are looking for "how to input scancodes on uhk" would be perfectly fine with "use macro:
press ALT
tap 1
tap 7
tap 8
relase ALT"
end of message.
Otherwise its like annoying clickbait article.
I respectfully disagree as most of our customers don't use Windows, so Windows-style Alt codes wouldn't be useful for them.
I am thinking about the investment of my own UHK. At the moment I am switching from the German QWERTZ Layout (Windows OS) to the KOY Layout which has six different layers (two of them are activated with a combination of two Fn keys). Is this basically possible?
I also had the chance to get my hands on an ErgoDox EZ from a friend of mine. But I don't like the layout and the keys are aranged in a funny way. But in the configuration there are plenty of opportunities to choose the different symbols etc. I am no expert and don't know, if they are language-related. As I understand the infos on this page it is not possible to send unicode characters, right?
And one more question: I played around with the online demo of the Agent. Is it possible to copy the layout from one layer to another layer?
Thanks a lot. It needs just a few more little steps for a purchase. ;)
Hi Axel, and thanks for considering supporting us!
I'm unsure whether activating a layer via multiple layer switcher keys is possible. Maybe it is via smart macros. Please open an issue, and my colleague will look into this.
USB keyboards, such as the UHK don't send characters to the host computer but scancodes, but it's possible to send any character this way. Please read this article for details.
I'm unsure exactly what you want to achieve, but I assume you want to copy-paste layers between keymaps which will be possible. Feel free to clarify.
Hello László, and thank you for the fast reply.
Concerning the layers I will raise an issue. Copy-paste-layers GIT issue (#1954) is exactly what I was talkink about.
I read the article and understand the problem (fairly). But maybe you can help me with one simple example and I can move onwards from there: I tried to implent the ´ (Alt code 0180) charakter in the only demo. But putting it into the search field doesn't find it and while recording it, I get only Alt + 0. What is the right way?
Alt codes vary between operating systems, so putting an Alt code into the scancode field won't display a relevant suggestion. You must create a macro starting with Key Action: Press Key: Alt, then a Type Text action of "0180", then Key Action: Release Key: Alt. Then you have to bind the macro to the relevant key.
Ah, okay! That was my missunderstanding. I didn't know, that I have to create macros for it. Thank you once again.